Code that changes together, stays together
Most of us are familiar with clean/layered/onion architecture - the tried and tested approach where code is organized in distinct layers with clear abstractions like controllers, services, and repositories.
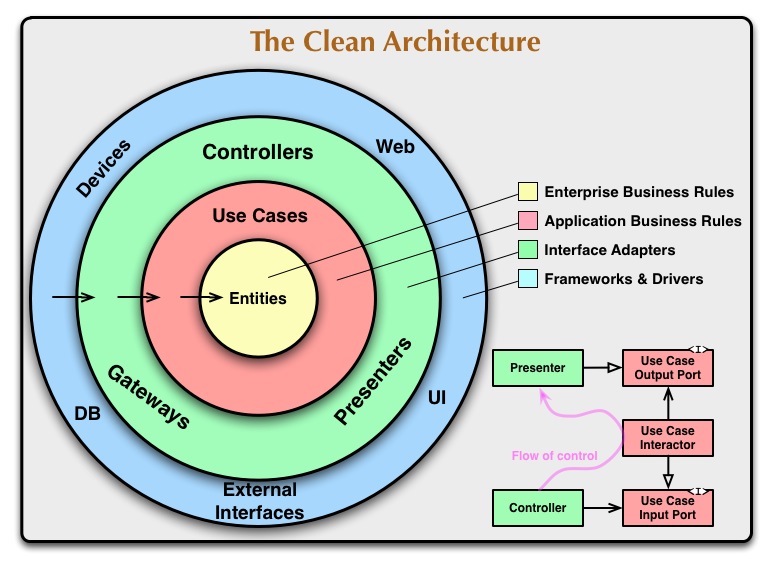
When implementing this architecture, I’ve noticed a common pattern: teams tend to organize their codebase strictly by these technical layers. You’ll typically see something like this:
1
2
3
4
5
6
- src
- controllers
- services
- use case
- entities
- repositories
Then, as projects grow and teams aim for a modular monolith, they often take the next “logical” step. They group these layers by what they believe are related features or modules:
1
2
3
4
5
6
7
8
9
10
11
12
13
- src
- module#1
- controllers
- services
- use case
- entities
- repositories
- module#2
- controllers
- services
- use case
- entities
- repositories
Here’s the thing though - I find this approach problematic. It forces teams to make critical structural decisions when they have the least understanding of their system. These early modularization attempts often feel artificial and constraining.
This got me thinking 🤔
- What if we could postpone these structural decisions until we truly understand our system better?
- How might we let the code structure evolve naturally, guided by actual usage patterns?
There was another pain point that kept bothering me: Making even a simple feature change required touching 4-5 different packages - updating the controller, tweaking the service, modifying the use case, and so on. All this ceremony just felt… excessive. I kept feeling that related code should live closer together.
Then it hit me, inspired by two familiar sayings:
“Neurons that fire together wire together” or “Family that eats together, stays together”
This led to what I consider a key insight:
Code that changes together, stays together
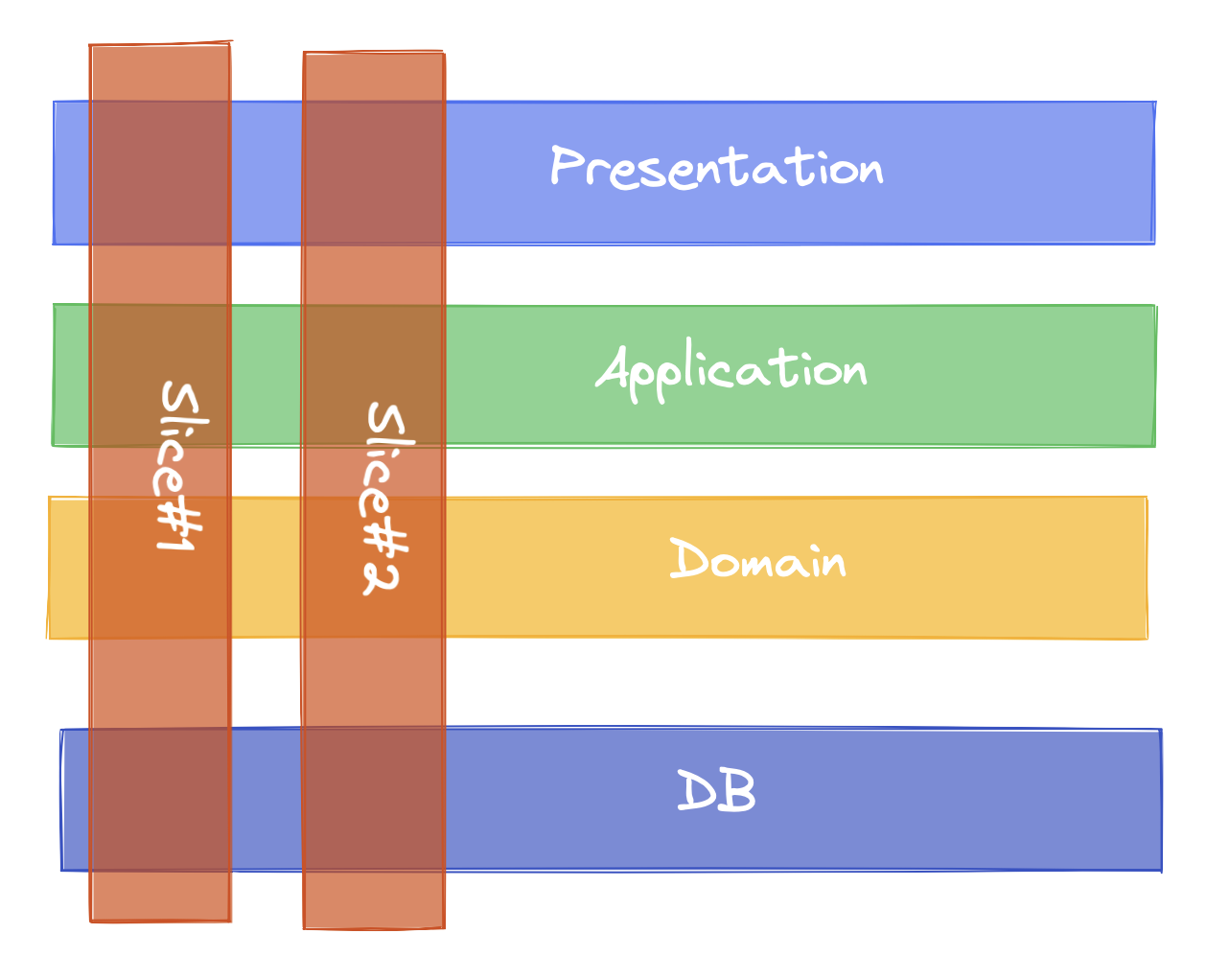
When I started moving frequently-changed code closer together, two interesting things emerged:
- Code within each feature slice became more tightly coupled (vertically) - and that was actually okay!
- Different feature slices became more loosely coupled from each other - a major win for maintainability.
The longer I worked with this approach, the more I noticed something fascinating: truly shared code naturally bubbled up to become either core domain concepts or cross-cutting concerns. These pieces found their rightful place not just in the codebase, but in our mental model of the system.
Here’s what made this approach particularly valuable:
- The code structure evolved organically as our understanding of the domain deepened
- We could be pragmatic about implementation within each slice
- The organization scaled naturally with our growing feature set
Here’s what the final structure typically looks like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- src
- todo
- api
- dto
- controller
- find-todos
- complete-todo
- new-todo
- todo
- notes
- api
- dto
- controller
- new-notes
- recent-notes
- note